Itthon először Szuhi Attila (ite.hu) adott hírt erről a szivárgásról és már itt írt is róla egy összefoglaló cikket: 2500 oldalnyi Google dokumentum, köztük rengeteg rangsorolási szignál szivárgott ki! Érdemes követni az ő cikkét, mert én most inkább a téma fontosságára való tekintettel (és hogy támogassam Attila munkásságát) készítettem el az eredeti angol cikk magyar változatát, a továbbiakban én is Attila híreit fogom követni.
Szerző: Rand Fishkin 2024, május 27.
Forrás: sparktoro.com
Május 5-én, vasárnap egy e-mailt kaptam egy ismeretlen személytől, aki azt állította, hogy hozzáférése van a Google keresési részlegének hatalmas mennyiségű kiszivárgott API dokumentációjához. Az e-mail továbbá azt állította, hogy ezeket a kiszivárgott dokumentumokat volt Google alkalmazottak hitelesítették, és hogy ezek a volt alkalmazottak és mások további, bizalmas információkat osztottak meg a Google keresési műveleteiről.
Állításaik közül sok közvetlenül ellentmond a Google-alkalmazottak által az évek során tett nyilvános nyilatkozatoknak, különösen a vállalat többszöri tagadásának, hogy kattintás-központú felhasználói jeleket alkalmaznának, tagadták, hogy az aldomaineket külön vennék figyelembe a rangsorolásban, tagadták az újabb weboldalak „sandbox”-olását („karanténba” helyezését), tagadták, hogy egy domain korát gyűjtenék vagy figyelembe vennék, és így tovább.
Természetesen szkeptikus voltam. A forrás (aki névtelenséget kért) által tett állítások rendkívülinek tűntek – íme néhány példa:
- A Google keresési csapata a korai években felismerte, hogy a webes felhasználók nagy százalékának teljes kattintás-adatfolyamára (minden URL-re, amelyet a böngésző meglátogat) van szükségük a keresőmotor eredményeinek minőségi javításához.
- Egy „NavBoost” nevű rendszer (amelyet Pandu Nayak, a Search alelnöke említett a DOJ ügyben tett vallomásában) kezdetben a Google Toolbar PageRank adatait gyűjtötte, és a több kattintási adatfolyam iránti vágy volt a fő motiváció a Chrome böngésző létrehozására (2008-ban indult).
- A NavBoost a keresések számát használja egy adott kulcsszóra a trendet mutató keresési igény azonosításához, a keresési találatra történő kattintások számát (erről 2013-2015 között több kísérletet is végeztem), valamint a hosszú és rövid kattintásokat (amiről ebben a 2015-ös videóban osztottam meg elméleteimet).
- A Google a cookie előzményeket, a bejelentkezett Chrome adatokat és a mintafelismerést (a kiszivárgott anyagban „nem elnyomott” kontra „elnyomott” kattintásokként említik) használja a manuális és automatizált kattintási spam elleni hatékony eszközként.
- A NavBoost a lekérdezéseket is pontozza a felhasználói szándék alapján. Például a videókra vagy képekre irányuló figyelem és kattintások bizonyos küszöbértékei aktiválják a videó vagy kép funkciókat az adott lekérdezéshez és a kapcsolódó, NavBoost-tal társított lekérdezésekhez.
- A Google megvizsgálja a kattintásokat és az elkötelezettséget a fő lekérdezés során és után is (ezt „NavBoost lekérdezésnek” nevezik). Ha például sok felhasználó a „Rand Fishkin”-re keres rá, nem találja meg a SparkToro-t, és azonnal megváltoztatja a lekérdezését „SparkToro”-ra, és a keresési találatban a SparkToro.com-ra kattint, akkor a SparkToro.com (és a „SparkToro”-t említő weboldalak) növekedést kapnak a „Rand Fishkin” kulcsszó keresési eredményeiben.
.. és ez még csak a jégjegy csúcsa.
A rendkívüli állítások rendkívüli bizonyítékokat igényelnek. És bár ezek közül néhány átfedésben van a Google/DOJ ügy során feltárt információkkal (amelyekről ebben a 2020-as témában olvashatsz), sok újdonság és bennfentes tudásra utal.
Szóval múlt pénteken, május 24-én (több e-mailt követően) videóhívást folytattam a névtelen forrással.
Az e-mail és a hívás előtt sem találkoztam, sem nem hallottam arról a személyről, aki erről a kiszivárgásról e-mailt küldött nekem. Azt kérték, hogy személyazonosságuk rejtve maradjon, és csak az alábbi idézetet tüntessem fel:
„A sas a vihart használja, hogy elképzelhetetlen magasságokba jusson.”
– Matshona Dhliwayo
A hívás után sikerült megerősítenem a munkamúltjuk részleteit, azokat a közös embereket, akiket mindketten ismerünk a marketing világából, és számos állításukat arról, hogy iparági bennfentesekkel (köztük Google-alkalmazottakkal) vettek részt különböző eseményeken, bár nem tudom megerősíteni a találkozók részleteit, sem azoknak a beszélgetéseknek a tartalmát, amelyeket állításuk szerint folytattak.
A hívás során ez a kapcsolat megmutatta nekem magát a kiszivárgott anyagot: több mint 2500 oldalnyi API dokumentációt, amely 14 014 attribútumot (API funkciót) tartalmaz, és úgy tűnik, hogy a Google belső „Content API Warehouse”-ából származik. A dokumentum verzióelőzményei alapján ezt a kódot 2024. március 27-én töltötték fel a GitHub-ra, és csak 2024. május 7-én távolították el.
Ez a dokumentáció nem mutatja meg olyan dolgokat, mint az egyes elemek súlya a keresési rangsorolási algoritmusban, és azt sem bizonyítja, hogy mely elemeket használják a rangsorolási rendszerekben. Viszont hihetetlen részleteket mutat arról, hogy a Google milyen adatokat gyűjt. Íme egy példa a dokumentum formátumára:

Képernyőkép a kiszivárgott adatokról a „jó” és „rossz” kattintásokkal kapcsolatban, beleértve a kattintások hosszát is (vagyis hogy mennyi időt tölt egy látogató egy weboldalon, amire a Google keresési eredményeiből kattintott, mielőtt visszatérne a keresési eredményekhez)
Miután végigvezetett az API modulok egy részén, a forrás elmagyarázta a motivációit (az átláthatóság, a Google elszámoltathatósága stb. körül), és azt a reményét, hogy publikálok egy cikket, amelyben megosztom ezt a kiszivárgást, felfedek néhány érdekes adatot, amit tartalmaz, és megcáfolok néhány „hazugságot”, amiket a Google alkalmazottak „évek óta terjesztenek”.
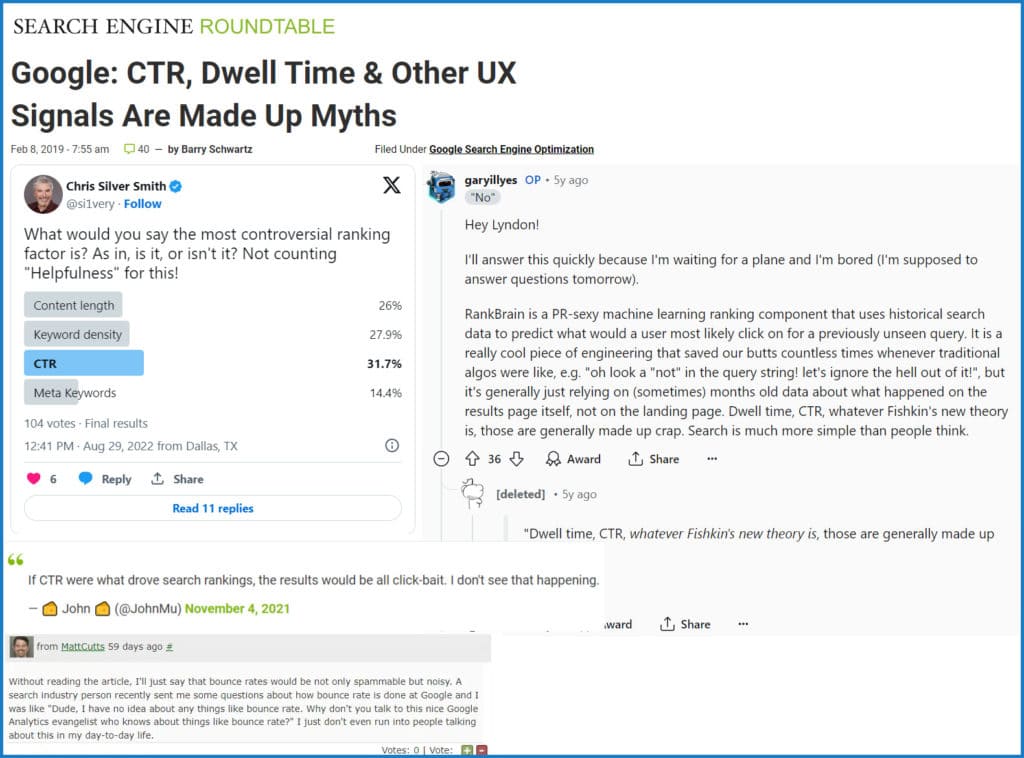
Példák a Google képviselőinek (Matt Cutts, Gary Ilyes és John Mueller) nyilatkozataira, amelyekben az elmúlt években tagadták a kattintás-alapú felhasználói jelek használatát a rangsorolásban
Tartalomjegyzék
Hiteles ez az API kiszivárgás? Megbízhatunk benne?
A folyamat következő kritikus lépése az API Content Warehouse dokumentumok hitelességének ellenőrzése volt. Ezért kapcsolatba léptem néhány volt Google-os barátommal, megosztottam velük a kiszivárgott dokumentumokat, és megkérdeztem a véleményüket. Három ex-Google-alkalmazott írt vissza: az egyik azt mondta, hogy nem érzi kényelmesnek, hogy megnézze vagy kommentálja. A másik kettő az alábbiakat osztotta meg (nem hivatalosan és névtelenül):
- „Nem volt hozzáférésem ehhez a kódhoz, amikor ott dolgoztam. De ez biztosan legitimnek tűnik.”
- „Minden jele megvan annak, hogy ez egy belső Google API.”
- „Ez egy Java-alapú API. És valaki sok időt töltött azzal, hogy betartsa a Google saját belső dokumentációs és elnevezési szabványait.”
- „Több időre lenne szükségem, hogy biztos legyek benne, de ez megfelel azoknak a belső dokumentációknak, amelyeket ismerek.”
- „Semmi olyat nem láttam egy rövid áttekintés során, ami arra utalna, hogy ez nem valódi.”
Ezután segítségre volt szükségem az elnevezési konvenciók és a dokumentáció technikai szempontjainak elemzéséhez és megfejtéséhez. Dolgoztam már egy kicsit API-kkal, de 20 éve nem írtam kódot, és 6 éve nem gyakoroltam professzionálisan az SEO-t. Ezért felvettem a kapcsolatot a világ egyik vezető technikai SEO szakemberével: Mike King-gel, az iPullRank alapítójával.
Egy péntek délutáni 40 perces telefonbeszélgetés során Mike átnézte a kiszivárgott anyagot, és megerősítette a gyanúmat: úgy tűnik, hogy ez a Google keresési részlegének belső dokumentumainak hiteles készlete, és rendkívül sok olyan információt tartalmaz a Google belső működéséről, amelyeket korábban nem erősítettek meg.
2500 technikai dokumentum ésszerűtlen mennyiségű anyag ahhoz, hogy egyetlen embertől (ráadásul apától, férjtől és vállalkozótól) kérjük, hogy egyetlen hétvége alatt átnézze. De ez nem akadályozta meg Mike-ot abban, hogy megtegye, ami tőle telik.
Összeállított egy kivételesen részletes kezdeti áttekintést a Google API kiszivárgásról itt, amelyre az alábbiakban még hivatkozni fogok. Valamint beleegyezett, hogy csatlakozik hozzánk a SparkTogether 2024 rendezvényen a washingtoni Seattle-ben, október 8-án, ahol sokkal részletesebben és a következő néhány hónap elemzésének előnyével mutatja be a kiszivárgás teljesen transzparens történetét.
A bejegyzés háttere és motivációi
Mielőtt továbbmennénk, néhány fenntartás: Már nem dolgozom az SEO területén. Az SEO-val kapcsolatos tudásom és tapasztalatom több mint 6 éve elavult. Nincs meg a technikai szakértelmem vagy a Google belső működésével kapcsolatos ismereteim ahhoz, hogy elemezzek egy kiszivárgott API dokumentációt, és teljes bizonyossággal megállapítsam, hogy hiteles-e (ezért kértem Mike segítségét és a volt Google-alkalmazottak véleményét).
Akkor miért írok erről a témáról?
Azért, mert amikor beszéltem azzal a féllel, aki ezt az információt elküldte nekem, hitelesnek, megfontoltnak és mélyen hozzáértőnek találtam. Annak ellenére, hogy a beszélgetésbe mélyen szkeptikusan mentem bele, nem tudtam azonosítani semmilyen red flaget, sem rosszindulatú motivációt. Úgy tűnt, hogy ennek a személynek az egyetlen célja teljesen összhangban van az enyémmel: elszámoltatni a Google-t azokért a nyilvános nyilatkozatokért, amelyek ellentmondanak a magánbeszélgetéseknek és a kiszivárgott dokumentációnak, és nagyobb átláthatóságot biztosítani a keresőmarketing területén. És úgy vélték, hogy az SEO-tól való évek óta tartó távollétem ellenére én vagyok a legalkalmasabb személy arra, hogy ezt nyilvánosan megosszam.
Ezek olyan célok, amelyek közel két évtizeden át mélyen érdekeltek. És bár a szakmai életem továbbment (most két céget vezetek: a SparkToro-t, amely közönségkutatási szoftvereket készít, és a Snackbar Studio-t, egy indie videojáték-fejlesztőt), a keresőoptimalizálás világa iránti érdeklődésem és kapcsolataim továbbra is erősek. Mély kötelességemnek érzem, hogy információkat osszak meg arról, hogyan működik a világ domináns keresőmotorja, különösen olyan információkat, amelyeket a Google inkább titokban tartana. És sajnos nem vagyok benne biztos, hogy hová máshová küldhetnék egy ilyen potenciálisan úttörő anyagot.
Évekkel ezelőtt, mielőtt otthagyta az újságírást, hogy a Google keresési összekötője legyen, Danny Sullivan lett volna az első számú forrásom egy ilyen horderejű kiszivárogtatáshoz. Megvolt a tekintélye, az önéletrajza, a tudása és a tapasztalata ahhoz, hogy megvizsgáljon egy ilyen állítást, és tisztességesen mutassa be a nyilvánosság előtt. Az elmúlt néhány évben sokszor kívántam Danny nyugodt, kiegyensúlyozott, a Google-lal szemben kemény, de fair hozzáállását az ilyen hírértékű cikkekhez – olyan cikkekhez, amelyek akár a vállalat tanúvallomásáig is eljuthatnak (pl. az ékesszóló írása a Google organikus keresési kifejezésekkel kapcsolatos, védhetetlen adatvédelmi állításairól).
Bármit is fizet neki a Google, az nem elég.
Először is hadd osszak meg pár dolgot a háttérről és hitelességről, mivel lehet, hogy kedves olvasóm nem igazán ismeri a szakmai múltamat:
- 2001-ben kezdtem SEO-val foglalkozni seattle-i kisvállalkozások számára, majd 2003-ban társalapítója voltam annak az SEO tanácsadó cégnek, amiből később a Moz lett (eredetileg SEOmoz néven).
- A következő 15 évben a keresőmarketing iparágban dolgoztam, és gyakran ismertek el befolyásos vezetőként ezen a területen. Szerzője/társszerzője voltam a Lost and Founder: A Painfully Honest Field Guide to the Startup World, The Art of SEO és az Inbound Marketing and SEO című könyveknek.
- Olyan kiadványok írtak rólam és idéztek engem az SEO és a Google keresés világával kapcsolatban, mint a WSJ, az Inc, a Forbes és sok száz másik, sokan közülük hivatkozva egy népszerű heti videósorozatra, amelyet egy évtizeden át vezettem: Whiteboard Friday.
- A Moz 35 000+ fizető ügyfélre, 50 millió dollárt meghaladó bevételre és ~200 fős csapatra nőtt, mielőtt 2021-ben eladták egy magántőke-befektetőnek. 2018-ban eljöttem, és elindítottam a SparkToro-t, majd 2023-ban a Snackbar Studio-t.
- 2001-ben kimaradtam a washingtoni egyetemről, és nincs diplomám, ennek ellenére a Google-lal és az SEO-val kapcsolatos munkámat idézte az Egyesült Államok Kongresszusa, az USA Szövetségi Kereskedelmi Bizottsága, a Wall Street Journal, a New York Times, és John Oliver Last Week Tonight műsora, sok más mellett.
- Több szabadalmam van a webméretű linkindex tervezésével kapcsolatban, és számos linkindex-metrika megalkotója vagyok, beleértve a Domain Authority-t, egy gépi tanuláson alapuló pontszámot, amelyet a digitális marketing világában általánosan használnak egy weboldal Google keresőben való rangsorolási képességének értékelésére.
Szóval ennyi a háttérről. Remélem ez segít megérteni, miért is tartottam fontosnak, hogy megvizsgáljam és megosszam ezt a potenciálisan nagy horderejű kiszivárgást a Google keresési rendszerének belső működéséről.
Rendben, akkor térjünk vissza a Google kiszivárogtatásához.
Mi az a Google API Content Warehouse?
Amikor átnézed a hatalmas API dokumentációs halmazt, az első ésszerű kérdések talán ezek lehetnek: „Mi ez? Mire használják? Miért létezik egyáltalán?”
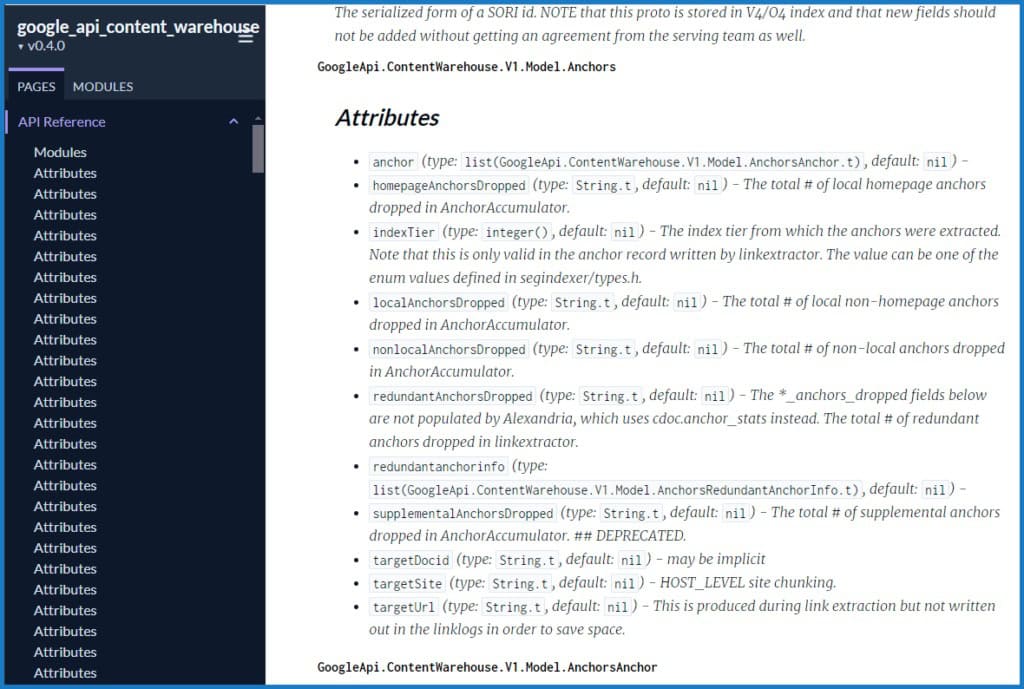
Úgy tűnik, hogy a szivárgás a GitHub oldaláról származik, és a legvalószínűbb magyarázat a kiszivárgásra az, amit az anonim forrásom is elmondott a telefonbeszélgetésünk során: ezek a dokumentumok véletlenül és rövid időre nyilvánosságra kerültek (sok link a dokumentációban privát GitHub repókhoz és Google vállalati oldalának belső oldalaihoz vezet, amelyekhez specifikus, Google-hitelesítő bejelentkezés szükséges). Ebben a valószínűleg véletlen, nyilvános időszakban 2024 márciusa és májusa között, az API dokumentáció eljutott a Hexdocs-hoz (amely nyilvános GitHub repókat indexel), és más források is megtalálták és terjesztették (biztos vagyok benne, hogy másoknak is van másolata, bár furcsa, hogy eddig nem találtam nyilvános vitát róla).
Volt Google-munkatársaim szerint az ilyen dokumentációk szinte minden Google-csapatnál léteznek, amelyek az egyes API attribútumokat és modulokat magyarázzák, hogy segítsenek a projektben dolgozóknak megismerkedni a rendelkezésre álló adatelemekkel. Ez a szivárgás megfelel más nyilvános GitHub repókban és a Google Cloud API dokumentációjában található szivárgásoknak, ugyanazt a jelölési stílust, formázást, sőt, ugyanazokat a folyamat/modul/funkció neveket és hivatkozásokat használva.
Ha ez mind túl technikai hangzású, gondolj rá úgy, mint a Google keresőcsapatának tagjainak szóló útmutatóra. Olyan, mint egy könyvtár leltára, egyfajta katalógus, amely elmondja azoknak az alkalmazottaknak, akiknek szükségük van rá, hogy mi érhető el és hogyan érhetik el.
Viszont míg a könyvtárak nyilvánosak, a Google keresője az egyik legtitkosabb, legszigorúbban őrzött fekete doboz a világon. Az elmúlt negyed évszázadban soha nem jelentettek ilyen mértékű vagy részletességű szivárgást a Google keresési részlegéről.
Mennyire lehetünk biztosak abban, hogy a Google keresőmotorja mindent használ, ami ezekben az API dokumentációkban szerepel?
Ez nyitott kérdés. Előfordulhat, hogy a Google már néhányat nyugdíjazott ezek közül, másokat kizárólag tesztelésre vagy belső projektekhez használt, vagy akár olyan API funkciókat is elérhetővé tett, amelyeket soha nem alkalmaztak.
A dokumentációban azonban vannak utalások elavult funkciókra, és egyes esetekben konkrét megjegyzések arra vonatkozóan, hogy azokat már nem szabad használni. Ez erősen arra utal, hogy azok, amelyek nincsenek ilyen részletekkel megjelölve, még aktív használatban voltak a 2024 márciusi kiszivárgás idején.
Azt sem lehet biztosan állítani, hogy a márciusi kiszivárgás a dokumentáció legfrissebb verziója-e. A legutóbbi dátum, amelyre az API dokumentációban hivatkoznak, 2023 augusztusa:
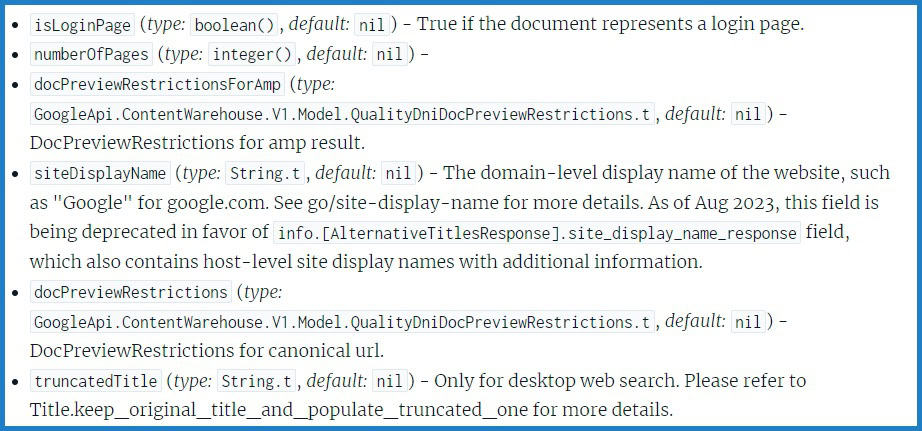
A vonatkozó szöveg a következő:
„A weboldal domain szintű megjelenítendő neve, például a „Google” a google.com esetében. További részletekért lásd a go/site-display-name oldalt. 2023 augusztusától kezdve ez a mező elavulttá válik az info.[AlternativeTitlesResponse].site_display_name_response mező javára, amely a host szintű webhelymegjelenítési neveket is tartalmazza további információkkal.„
Egy értelmes olvasó arra a következtetésre jutna, hogy a dokumentáció a múlt nyárig naprakész volt (a 2023-as és a korábbi évek más változásaira való hivatkozások, egészen 2005-ig visszamenőleg, szintén jelen vannak), és esetleg még a kiszivárgás 2024 márciusi dátumáig is naprakész volt.
A Google keresés nyilvánvalóan hatalmas változásokon megy keresztül évről évre, és az olyan újdonságok, mint a sokat bírált AI áttekintések, nem jelennek meg ebben a kiszivárgásban. Az említett elemek közül melyeket használják aktívan ma a Google rangsorolási rendszereiben? Ez találgatás kérdése. Ez a kincs olyan érdekes hivatkozásokat tartalmaz, amelyek közül sok teljesen új lesz a nem Google keresőmérnökök számára.
De arra kérném az olvasókat, hogy ne mutassanak egy adott API funkcióra ebben a szivárgásban, és mondják azt: „LÁTOD! Ez bizonyíték arra, hogy a Google XYZ-t használja a rangsorolásban.” Ez nem bizonyíték. Erős jelzés, erősebb, mint a szabadalmi bejelentések vagy a Google dolgozóinak nyilvános kijelentései, de még mindig nem garancia.
Ettől függetlenül ez a legközelebbi a perdöntő bizonyítékhoz, mint bármi más azóta, hogy a Google vezetői tavaly vallomást tettek az Igazságügyi Minisztérium perében. És ha már szó esett erről a tanúvallomásról, annak nagy részét a dokumentumszivárgás is megerősíti és kibővíti, ahogyan azt Mike részletezi a bejegyzésében.
Mit tanulhatunk a Data Warehouse szivárgásból?
Úgy gondolom, hogy érdekes és a marketing szempontjából hasznos betekintések fognak kiderülni ebből a hatalmas fájlkészletből az elkövetkező évek során. Egyszerűen túl nagy és túl sűrű ahhoz, hogy egy hétvégi böngészéssel átfogó következtetéseket lehessen levonni, vagy akár közel kerülni ehhez.
Azonban megosztok öt legérdekesebb, korai felfedezést az általam átnézett dokumentumokból, amelyek némelyike új fényt vet a Google által régóta feltételezett tevékenységekre, míg mások azt sugallják, hogy a vállalat nyilvános kijelentései (különösen azok, amelyek arról szólnak, hogy mit „gyűjtenek”) tévesek voltak. Mivel ez fárasztó lenne és személyes sérelmekként is értelmezhető (tekintve a Google történelmi támadásait a munkám ellen), nem fogok részletes összehasonlításokat mutatni a Google munkatársainak kijelentései és a dokumentumok sugallatai között. Emellett Mike nagyszerű munkát végzett ebben a posztjában.
Ehelyett az érdekes és/vagy hasznos tanulságokra összpontosítok, valamint az általam átnézett modulokból és Mike írásából levont következtetéseimre, és arra, hogy ezek hogyan illeszkednek a Google-ról ismert egyéb tényekhez.
#1: Navboost és a kattintások, CTR, hosszú vs. rövid kattintások és felhasználói adatok használata
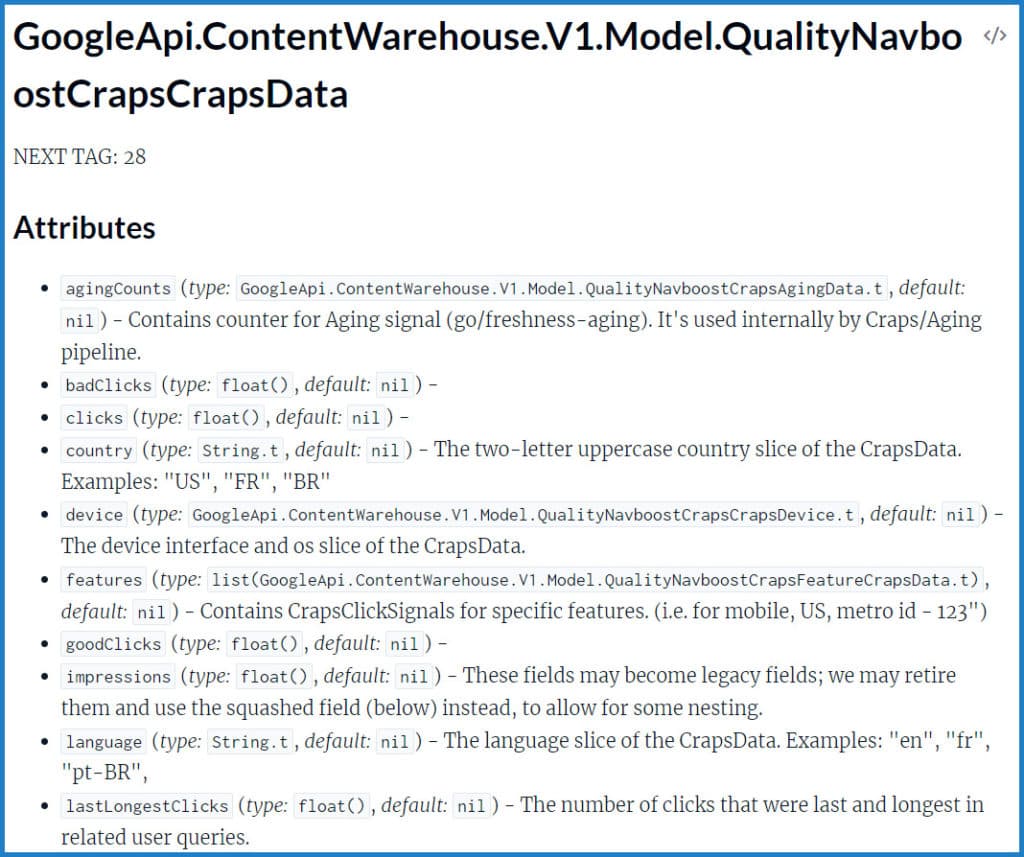
A dokumentációban néhány modul olyan funkciókra hivatkozik, mint a “goodClicks,” “badClicks,” “lastLongestClicks,” megjelenítések (impressions), squashed, unsquashed, és unicorn clicks. Ezek a Navboosthoz és a Glue-hoz kapcsolódnak, két olyan szóhoz, amely ismerős lehet azoknak, akik átnézték a Google DOJ vallomását. Íme egy releváns részlet Kenneth Dintzer DOJ ügyvéd keresztkérdéseiből, melyeket Pandu Nayaknak, a Keresési Minőség csapat alelnökének tett fel:
Kérdés: Tehát emlékeztessen, a navboost egészen 2005-ig visszanyúlik?
Válasz: Valahol abban az időszakban. Talán még előtte is.
K: És ezt frissítették. Ez nem ugyanaz a régi navboost, mint akkoriban?
V: Nem.
K: És egy másik a glue, igaz?
V: A Glue csak egy másik név a navboost számára, amely tartalmazza az oldal összes többi funkcióját is.
K: Rendben. Erre később tértem volna rá, de most is megtehetjük. A navboost webes találatokat csinál, igaz?
V: Igen.
K: És a glue mindent mást csinál az oldalon, ami nem webes találat, igaz?
V: Ez így van.
K: Együtt segítenek megtalálni és rangsorolni azokat a dolgokat, amelyek végül megjelennek a SERP-ünkön?
V: Ez igaz. Mindkettő jelzés ehhez, igen.
Az API dokumentumok hozzáértő olvasói megtalálhatják, hogy ezek támogatják Mr. Nayak vallomását (és összhangban vannak a Google szabadalmával a webhelyek minőségéről):
- Quality Navboost Data module
- Navboost Data geo-szegmentálása
- Kattintásjelek a Navboostban
- Adatok öregedése, megjelenítések és kattintások
A Google úgy tűnik, hogy képes kiszűrni azokat a kattintásokat, amelyeket nem szeretne figyelembe venni a rangsorolási rendszereiben, és beépíteni azokat, amelyeket igen. Úgy tűnik, hogy mérik a kattintások hosszát is (azaz a pogo-sticking – amikor a kereső egy találatra kattint, majd gyorsan visszalép, mert nem elégedett a talált válasszal) és a megjelenítéseket.
Már sokat írtak a Google kattintási adatok használatáról, így nem fogom túl részletesen kifejteni. Ami fontos, az az, hogy a Google elnevezte és leírta ezeket a mérési funkciókat, ami még több bizonyítékot szolgáltat erre a területre.
#2: A Chrome böngésző kattintási adatainak felhasználása a Google Kereséshez

Anonim forrásom szerint a Google már 2005-ben szerette volna megszerezni az internetezők teljes kattintásfolyamát, és a Chrome segítségével most meg is tették ezt. Az API dokumentumok arra utalnak, hogy a Google többféle mérőszámot számít ki, amelyeket a Chrome nézetek segítségével lehet elérni, mind az egyes oldalakra, mind az egész domainre vonatkozóan.
Különösen érdekes ez a dokumentum, amely leírja, hogyan hozza létre a Google a Sitelinkeket. Bemutat egy topUrl nevű hívást, amely „A legmagasabb two_level_score értékkel rendelkező top URL-ek listája, azaz chrome_trans_clicks.” Az olvasatom szerint a Google valószínűleg a Chrome böngészőkben az oldalakra leadott kattintások számát használja fel annak meghatározására, hogy melyek a legnépszerűbb/fontosabb URL-ek egy webhelyen, és ezek alapján számítja ki, melyeket vegyen be a Sitelinkek funkcióba.
Például, a fenti képernyőkép alapján a Google eredményeiben az olyan oldalak, mint az „Árak”, a „Blog” és a „Bejelentkezés” a leglátogatottabbak, és a Google ezt a több milliárd Chrome felhasználó kattintásainak nyomon követésével tudja.
#3: Fehérlisták (WhiteList = kivételek) az Utazás, a Covid és a Politika terén
Egy „Jó minőségű utazási oldalak” modul arra a következtetésre vezethet, hogy a Google-nak van egy fehérlistája az utazási szektorban (nem világos, hogy ez kizárólag a Google „Utazás” keresési lapjára vonatkozik-e, vagy szélesebb körben a webes keresésre). Több helyen is találhatók utalások az „isCovidLocalAuthority” és „isElectionAuthority” zászlókra, amelyek tovább sugallják, hogy a Google fehérlistázza azokat a domaineket, amelyek megfelelőek a nagyon ellentmondásos vagy potenciálisan problémás lekérdezésekhez.
Például, a 2020-as amerikai elnökválasztás után az egyik jelölt (bizonyíték nélkül) azt állította, hogy az elnökválasztást elcsalták, és arra buzdította követőit, hogy ostromolják meg a Capitolt és vegyenek részt esetleg erőszakos cselekményekben a törvényhozók ellen, azaz kövessenek el lázadást.
A Google szinte biztosan az egyik első hely lenne, ahova az emberek fordulnának információért az eseménnyel kapcsolatban, és ha keresőmotorjuk propaganda weboldalakat adna vissza, amelyek pontatlanul ábrázolják a választási bizonyítékokat, az közvetlenül vezethetne további feszültségekhez, erőszakhoz, vagy akár az amerikai demokrácia végéhez. Azoknak, akik szeretnék, hogy a szabad és tisztességes választások folytatódjanak, nagyon hálásnak kell lenniük, hogy a Google mérnökei ebben az esetben fehérlistákat alkalmaznak.
- Quality NSR Data Attributes
- Assistant API Settings for Music Filters
- Video Content Search Query Features
- Quality Travel Sites Data modul
#4: A Quality Rater visszajelzések alkalmazása

A Google már régóta rendelkezik egy minőségértékelő platformmal, az EWOK-kal (Cyrus Shepard, az SEO tér egyik kiemelkedő vezetője, több évet töltött ezzel, és itt írt róla). Most már bizonyítékunk van arra, hogy a minőségértékelők egyes elemeit a keresőrendszerekben is használják.
Hogy ezek a rater-alapú jelek mennyire befolyásosak, és pontosan mire használják őket, az első olvasatra nem teljesen világos, de gyanítom, hogy néhány gondos SEO nyomozó bele fog ásni a szivárgásba, tanul belőle, és többet fog publikálni róla. Ami számomra lenyűgöző, hogy az EWOK minőségértékelők által generált pontszámok és adatok közvetlenül részt vehetnek a Google keresőrendszerében, nem csupán kísérletekhez használt képzési adathalmazként. Természetesen lehetséges, hogy ezek „csak tesztelésre” szolgálnak, de ha végigböngésszük a kiszivárgott dokumentumokat, láthatjuk, hogy amikor ez igaz, azt külön megemlítik a jegyzetekben és a modul részleteiben.
Ebben a dokumentumban például szerepel egy „dokumentum szintű relevancia értékelés”, amely az EWOK segítségével végzett értékelésekből származik. Nincs részletes jegyzet, de nem nehéz elképzelni, mennyire fontosak ezek az emberi értékelések a webhelyekről.
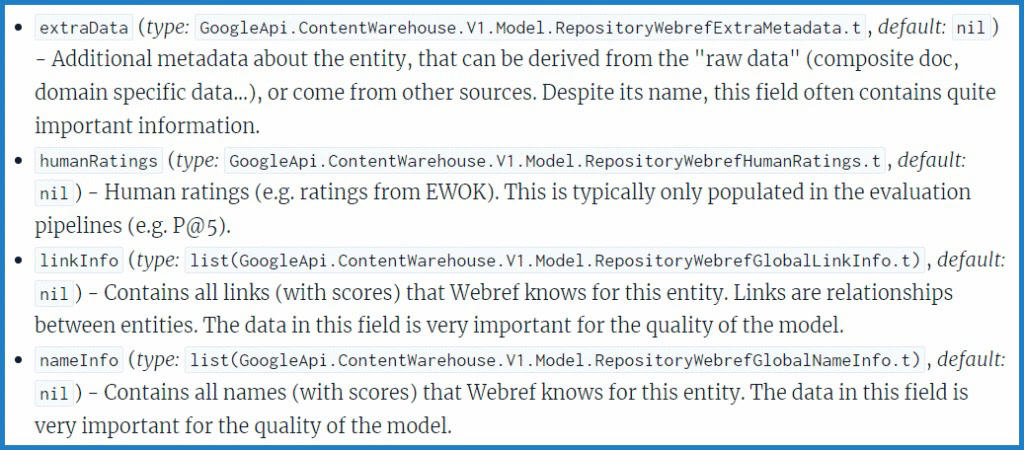
Ez a dokumentum „emberi értékeléseket (például az EWOK értékeléseit)” említi, és megjegyzi, hogy „általában csak az értékelési folyamatokban vannak kitöltve,” ami arra utal, hogy ezek elsősorban képzési adatként szolgálnak ebben a modulban (szerintem ez még mindig nagyon fontos szerep, és a marketingszakembereknek nem szabad elhanyagolniuk, mennyire fontos, hogy a minőségértékelők jól érzékeljék és értékeljék webhelyeiket).
- Webref Mention Ratings modul
- Webref Task Data modul
- Document Level Relevance modul
- Webref per Doc Relevance Rating modul
- Webref Entity Join
#5: A Google a kattintási adatokat használja a linkek súlyozásának meghatározására a rangsorolásban
Ez igazán lenyűgöző, és közvetlenül az anonim forrástól származik, aki először megosztotta a szivárgást. Az ő szavaival: „A Google három vödröt/szintet használ a linkindexeik osztályozására (alacsony, közepes, magas minőség). A kattintási adatokat használják annak meghatározására, hogy melyik linkgrafikon indexszinthez tartozik egy dokumentum. Lásd: SourceType itt, és TotalClicks itt.” Összefoglalva:
- Ha a Forbes.com/Cats/ oldalnak nincs kattintása, akkor az alacsony minőségű indexbe kerül, és a linket figyelmen kívül hagyják.
- Ha a Forbes.com/Dogs/ oldalnak nagy mennyiségű kattintása van ellenőrizhető eszközökről (az összes korábban tárgyalt Chrome-adat), akkor a magas minőségű indexbe kerül, és a link rangsorolási jeleket továbbít.
Miután a link „megbízhatóvá” válik, mert egy magasabb szintű indexhez tartozik, továbbíthatja a PageRank-et és az anchorokat, vagy a link spam rendszerek által szűrve/lefokozva lehet. Az alacsony minőségű linkindexből származó linkek nem ártanak egy webhely rangsorolásának; egyszerűen figyelmen kívül hagyják őket.
Ez a felfedezés különösen érdekes, mert betekintést nyújt abba, hogy a Google hogyan használja fel a kattintási adatokat a linkek minőségének értékelésére és rangsorolására. Azáltal, hogy a kattintási adatokat integrálják a linkek osztályozásába, a Google hatékonyabban tudja megkülönböztetni a valódi, hasznos linkeket a spamlinkektől, így javítva a keresési eredmények minőségét és relevanciáját.
Átfogó tanulságok a marketingszakemberek számára, akiknek fontos az organikus keresőforgalom
Ha stratégiailag fontos számodra az organikus keresőforgalom értéke, de nem igazán érdekelnek a technikai részletek arról, hogyan működik a Google, akkor ez a rész neked szól. Ez az én kísérletem arra, hogy összefoglaljam a Google fejlődését az ebben a szivárgásban lefedett időszakban: 2005–2023, és nem korlátozom magam kizárólag a szivárgás megerősített elemeire.
A márka mindennél fontosabb
A Google számos módon azonosítja, rendezi, rangsorolja és alkalmazza az entitásokat. Az entitások közé tartoznak a márkák (márkanevek, hivatalos weboldalak, kapcsolódó közösségi fiókok stb.), és ahogy azt a Datos-szal végzett kattintásfolyam-kutatásunkban láttuk, a Google folyamatosan egyre inkább a nagy, erős márkák rangsorolására és forgalomirányítására törekszik, amelyek uralják az internetet, szemben a kis, független webhelyekkel és vállalkozásokkal.
Ha lenne egy univerzális tanácsom a marketingszakemberek számára, akik szeretnék jelentősen javítani organikus keresési rangsorukat és forgalmukat, az az lenne: „Építs egy figyelemre méltó, népszerű, jól ismert márkát a saját területeden, a Google keresésen kívül.”
Tapasztalat, szakértelem, hitelesség és megbízhatóság (azaz „E-E-A-T”) **talán nem olyan közvetlenül fontos, mint ahogy azt egyes SEO szakemberek gondolják.
Az egyetlen említés a tematikus szakértelemről, amit eddig találtunk a szivárgásban, egy rövid jegyzet a Google Maps értékelések hozzájárulásairól. Az E-E-A-T többi aspektusa vagy elrejtve, közvetett módon, nehezen azonosítható módon van címkézve, vagy – véleményem szerint valószínűbb – olyan dolgokkal korrelál, amelyeket a Google használ és fontosnak tart, de nem specifikus elemei a rangsorolási rendszereknek.
Ahogy Mike a cikkében megjegyezte, van dokumentáció a szivárgásban, amely arra utal, hogy a Google képes azonosítani az írókat, és entitásként kezeli őket a rendszerben. Az online befolyás növelése íróként valóban rangsorolási előnyökhöz vezethet a Google-ben. Azonban, hogy pontosan mi alkotja az „E-E-A-T”-t a rangsorolási rendszerekben és mennyire erősek ezek az elemek, az nyitott kérdés. Attól tartok, hogy az E-E-A-T 80%-ban propaganda, 20%-ban lényeg. Számos erős márka, amely kiemelkedően jól rangsorol a Google-ben, nagyon kevés tapasztalattal, szakértelemmel, hitelességgel vagy megbízhatósággal rendelkezik, ahogy a HouseFresh legutóbbi, vírusos cikke részletesen bemutatja.
A tartalom és a linkek másodlagosak, amikor a felhasználói szándék a navigáció körül jelen van (és az ennek alapján kialakuló minták).
A tartalom és a linkek másodlagosak, amikor a navigációval kapcsolatos felhasználói szándék (és az általa létrehozott minták) jelen vannak.
Tegyük fel például, hogy Seattle környékén sokan rákeresnek a „Lehman Brothers” kifejezésre, és a keresési eredmények 2., 3. vagy 4. oldalára görgetnek, amíg meg nem találják a Lehman Brothers színházi előadás listáját, majd rákattintanak erre az eredményre. A Google viszonylag gyorsan megtanulja, hogy az adott területen ezekre a szavakra keresők mit akarnak.
Még ha a Lehman Brothers 2008-as pénzügyi válságban játszott szerepéről szóló Wikipédia-cikk sokat is fektetne a linképítésbe és a tartalom optimalizálásába, valószínűtlen, hogy felülkerekedhetne a Seattle-i színházlátogatók felhasználói szándékjelein (amelyeket a lekérdezésekből és kattintásokból számítanak ki).
Kiterjesztve ezt a példát a tágabb webre és a keresésre általában, ha elegendő valószínű keresőben tudsz keresletet teremteni a webhelyed iránt az általad megcélzott régiókban, lehetőséged nyílhat megkerülni a klasszikus on-page és off-page SEO jelek, például a linkek, a horgonyszövegek, az optimalizált tartalom és hasonlók szükségességét. A Navboost ereje és a felhasználók szándéka valószínűleg a legerősebb rangsorolási tényező a Google rendszereiben. Ahogyan Alexander Grushetsky, a Google alelnöke fogalmazott egy 2019-es e-mailben más Google vezetőknek (köztük Danny Sullivannek és Pandu Nayaknak):
„Már tudjuk, hogy egy jel erősebb lehet, mint az egész nagy rendszer egy adott metrikán. Például meglehetősen biztos vagyok benne, hogy a NavBoost önmagában pozitívabb volt/van a kattintásokra (és valószínűleg még a precíziós/hasznossági mérőszámokra is), mint a rangsorolás többi része (Mellesleg, a Navboost csapaton kívüli mérnökök sem voltak elégedettek a Navboost erejével, és azzal a ténnyel, hogy „ellopta a győzelmeket”)„
Azok, akik még több megerősítést keresnek, áttekinthetik Paul Haahr, a Google mérnökének részletes önéletrajzát, amely a következőket tartalmazza:
„Én vagyok a naplóalapú (log-based) rangsorolási projektek menedzsere. A csapat erőfeszítései jelenleg négy területre oszlanak: 1) Navboost. Ez már most is a Google egyik legerősebb rangsorolási jele. A jelenlegi munka az automatizáláson folyik az új navboost adatok építésében;„
A klasszikus rangsorolási tényezők: PageRank, horgonyszövegek (tematikus PageRank a link horgonyszövegén alapulva) és a szövegillesztés évek óta csökkenő jelentőségűek. Azonban az oldalcímek még mindig nagyon fontosak.
Ez Mike kiváló elemzésének egyik felfedezése, amelyet itt muszáj megemlítenem. A PageRank még mindig szerepet játszik a keresési indexelésben és rangsorolásban, de szinte biztosan továbbfejlesztették az eredeti 1998-as tanulmány óta. A dokumentumszivárgás többféle PageRank verzióra utal (rawPagerank, egy elavult PageRank, amely „legközelebbi magok” hivatkozik, firstCoveragePageRank az első megjelenéskor, stb.), amelyeket az évek során létrehoztak és elvetettek. És bár a horgonyszöveg linkek jelen vannak a szivárgásban, nem tűnnek olyan kulcsfontosságúnak vagy mindenütt jelenlévőnek, mint ahogy azt korábbi SEO-s éveimben vártam volna.
A legtöbb kis- és középvállalkozás és újabb alkotók/kiadók számára az SEO valószínűleg gyenge megtérülést mutat, amíg nem alakítanak ki hitelességet, navigációs keresletet és erős hírnevet egy jelentős közönség körében.
Az SEO a nagy márkák, népszerű domainek játéka. Vállalkozóként nem hagyom figyelmen kívül az SEO-t, de erősen számítok rá, hogy a következő években, amíg/amíg a SparkToro nem válik sokkal nagyobb, népszerűbb, keresettebb és kattintottabb márkává az iparágában, ez a weboldal továbbra is alulmarad, még saját eredeti tartalma esetében is, az aggregátorokkal és kiadókkal szemben, amelyek már több mint 10 éve léteznek.
Ez szinte biztosan igaz más alkotókra, kiadókra és kis- és középvállalkozásokra is. A létrehozott tartalom valószínűleg nem teljesít jól a Google-ban, ha ismert márkákkal rendelkező nagy, népszerű webhelyekkel kell versenyeznie. A Google már nem jutalmazza az agyafúrt, okos, SEO-ban jártas szereplőket, akik ismerik az összes megfelelő trükköt. Ők a már ismert márkákat, a keresésekkel mérhető népszerűségi formákat és azokat a bejáratott doméneket jutalmazzák, amelyeket a keresők már ismernek és rákattintanak. 1998 és 2018 (vagy valamikor akörül) között ésszerűen el lehetett indítani egy hatékony marketing lendkereket a Google SEO-jával. 2024-ben már nem hiszem, hogy ez reális lenne, legalábbis nem az angol nyelvű weben, a versengő szektorokban.
A keresőipar következő lépései
Alig várom, hogy lássam, hogyan elemzik ezt az adatszivárgást azok a szakemberek, akik frissebb tapasztalatokkal és mélyebb technikai ismeretekkel rendelkeznek. Bátorítok mindenkit, akit érdekel, hogy mélyedjen el a dokumentációban, próbálja meg összekapcsolni más nyilvános dokumentumokkal, nyilatkozatokkal, tanúvallomásokkal és rangsorolási kísérletekkel, majd tegye közzé az eredményeit.
Történelmileg a keresőipar leghangosabb hangjai és legtermékenyebb kiadói boldogan ismételték a Google nyilvános nyilatkozatait, anélkül, hogy kritikusan megvizsgálták volna azokat. Olyan címsorokat írnak, mint „A Google szerint az XYZ igaz”, ahelyett, hogy „A Google azt állítja, hogy XYZ; a bizonyítékok mást sugallnak”.

Az SEO ipar nem profitál az ilyen típusú címsorokból Kérlek, csináld jobban. Ha ez a kiszivárgás és a DOJ per csak egy változást tud előidézni, remélem, hogy ez lesz az.
Amikor az új belépők a Search Engine Roundtable-t, a Search Engine Land-et, az SE Journal-t és a sok ügynökségi blogot és weboldalt olvassák, amelyek az SEO szakma híreit fedik le, nem feltétlenül tudják, mennyire kell komolyan venni a Google nyilatkozatait. Az újságíróknak és szerzőknek nem szabad feltételezniük, hogy az olvasók elég hozzáértők ahhoz, hogy tudják, a Google hivatalos képviselőinek tucatnyi vagy több száz korábbi nyilvános megjegyzéséről később kiderült, hogy helytelenek.
Ez a kötelezettség nem csak a keresőipar segítéséről szól – az egész világot segíti. A Google az egyik legerősebb, legbefolyásosabb erő az információk terjesztésében és a kereskedelemben ezen a bolygón. Csak a közelmúltban vonták őket felelősségre a kormányok és az újságírók. A keresőmarketing területén dolgozó újságírók és írók munkája súlyt képvisel a közvélemény bíróságain, a választott tisztségviselők csarnokaiban és a Google alkalmazottak szívében, akik mindannyian képesek a dolgokat jobbá változtatni, vagy figyelmen kívül hagyni őket a kollektív veszélyünkre.
Köszönet Mike Kingnek az adatszivárgásról szóló cikkhez nyújtott felbecsülhetetlen segítségéért, Amanda Natividadnak a szerkesztési segítségért, valamint a névtelen forrásnak, aki megosztotta velem ezt a kiszivárgott anyagot. Arra számítok, hogy a következő napokban és hetekben frissítések érkezhetnek ehhez a cikkhez, ahogy egyre több szem elé kerül. Ha olyan megállapításaid vannak, amelyek alátámasztják vagy cáfolják az itt tett kijelentéseimet, kérlek, oszd meg őket az alábbi hozzászólásokban.
További linkek a témában:
- A kiszirvárgott dokumentáció: https://hexdocs.pm/google_api_content_warehouse/0.3.0/api-reference.html
- Elemzés Mike King segítségével: https://ipullrank.com/google-algo-leak
- kereshető formában: https://dixonjones.com/google-ranking-signals






